Grad-TTS: A Diffusion Probabilistic Model for Text-to-Speech
Authors: Vadim Popov, Ivan Vovk, Vladimir Gogoryan, Tasnima Sadekova, Mikhail Kudinov
Authors: Vadim Popov, Ivan Vovk, Vladimir Gogoryan, Tasnima Sadekova, Mikhail Kudinov
| ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀ |
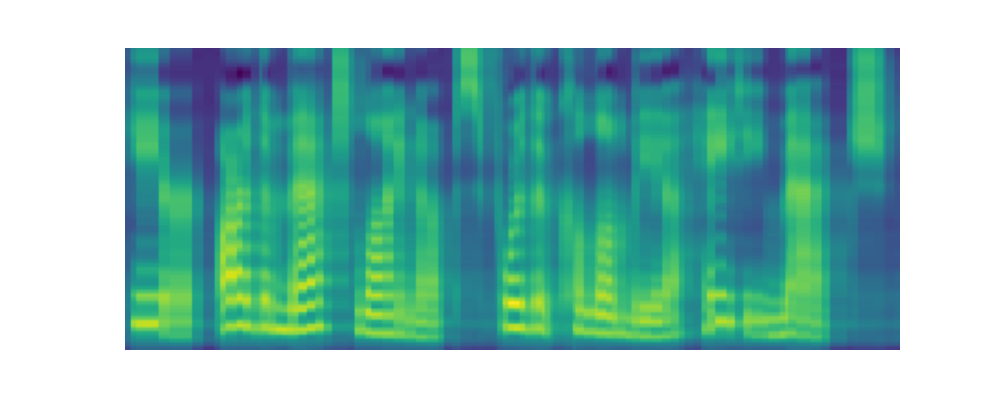
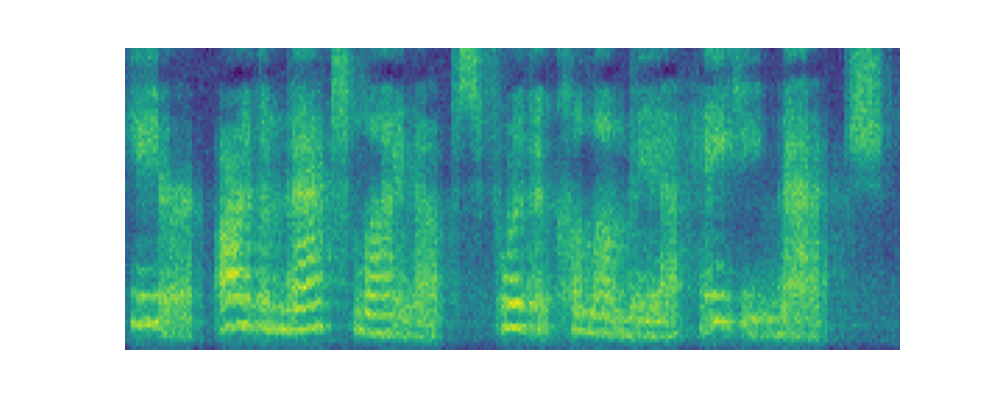
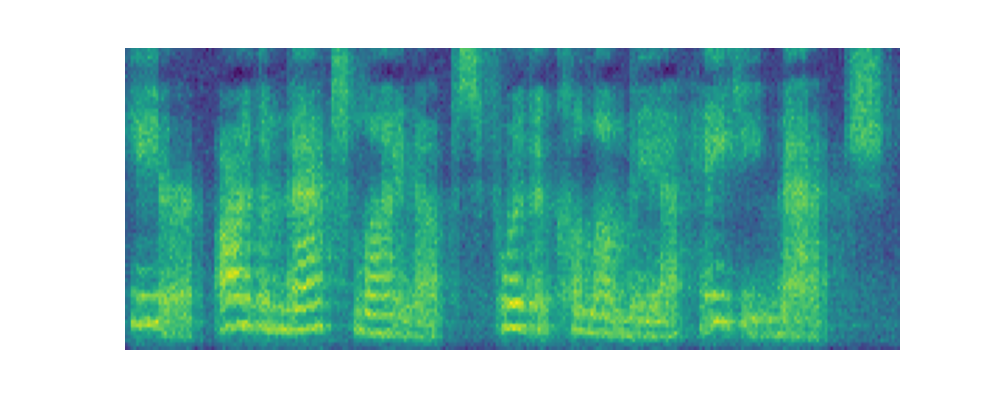
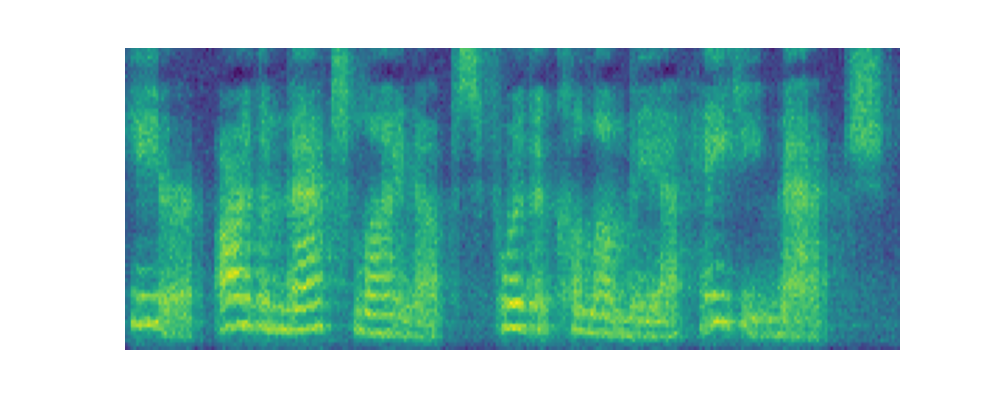
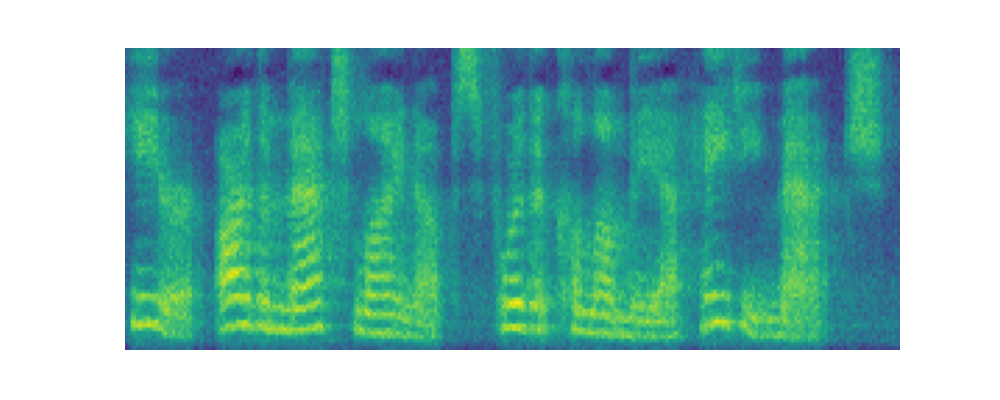
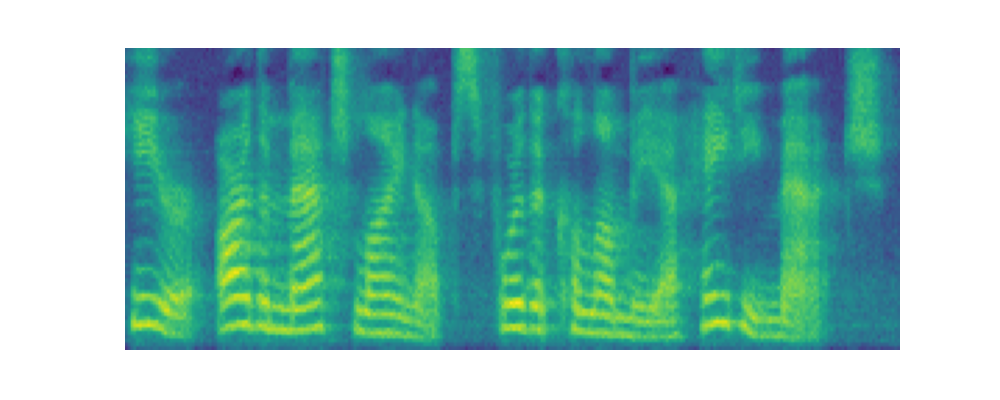
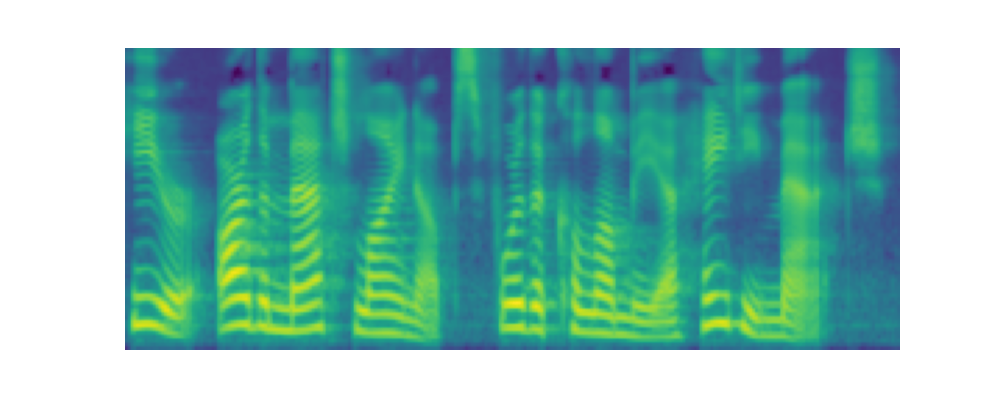
Paper on Arxiv: link. Official open-sourced implementation: link. Note: HiFi-GAN is used as vocoder. Also, listen to the audios using headphones for better experience. AbstractVoiced by our Grad-TTS model: Recently, denoising diffusion probabilistic models and generative score matching have shown high potential in modelling complex data distributions while stochastic calculus has provided a unified point of view on these techniques allowing for flexible inference schemes. In this paper we introduce Grad-TTS, a novel text-to-speech model with score-based decoder producing mel-spectrograms by gradually transforming noise predicted by encoder and aligned with text input by means of Monotonic Alignment Search. The framework of stochastic differential equations helps us to generalize conventional diffusion probabilistic models to the case of reconstructing data from noise with different parameters and allows to make this reconstruction flexible by explicitly controlling trade-off between sound quality and inference speed. Subjective human evaluation shows that Grad-TTS is competitive with state-of-the-art text-to-speech approaches in terms of Mean Opinion Score. Illustration of mel-spectrogram reconstruction process for 50 refinement steps:Note: Grad-TTS-50 model is considered. In this section we show intermediate mel-spectrogram states from score-based decoder in order to illustrate how reverse diffusion works. Text: Here are the match lineups for the Colombia Haiti match. 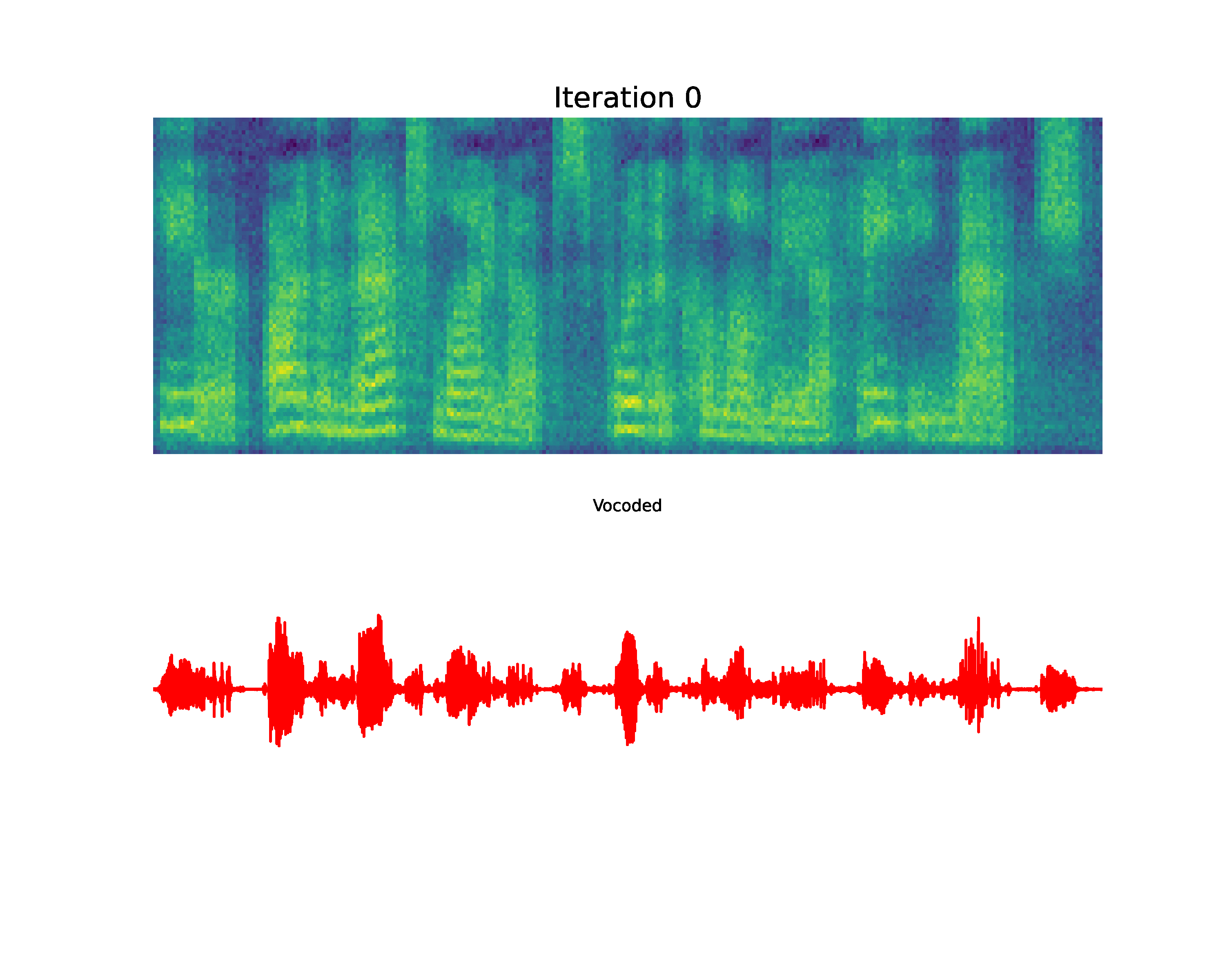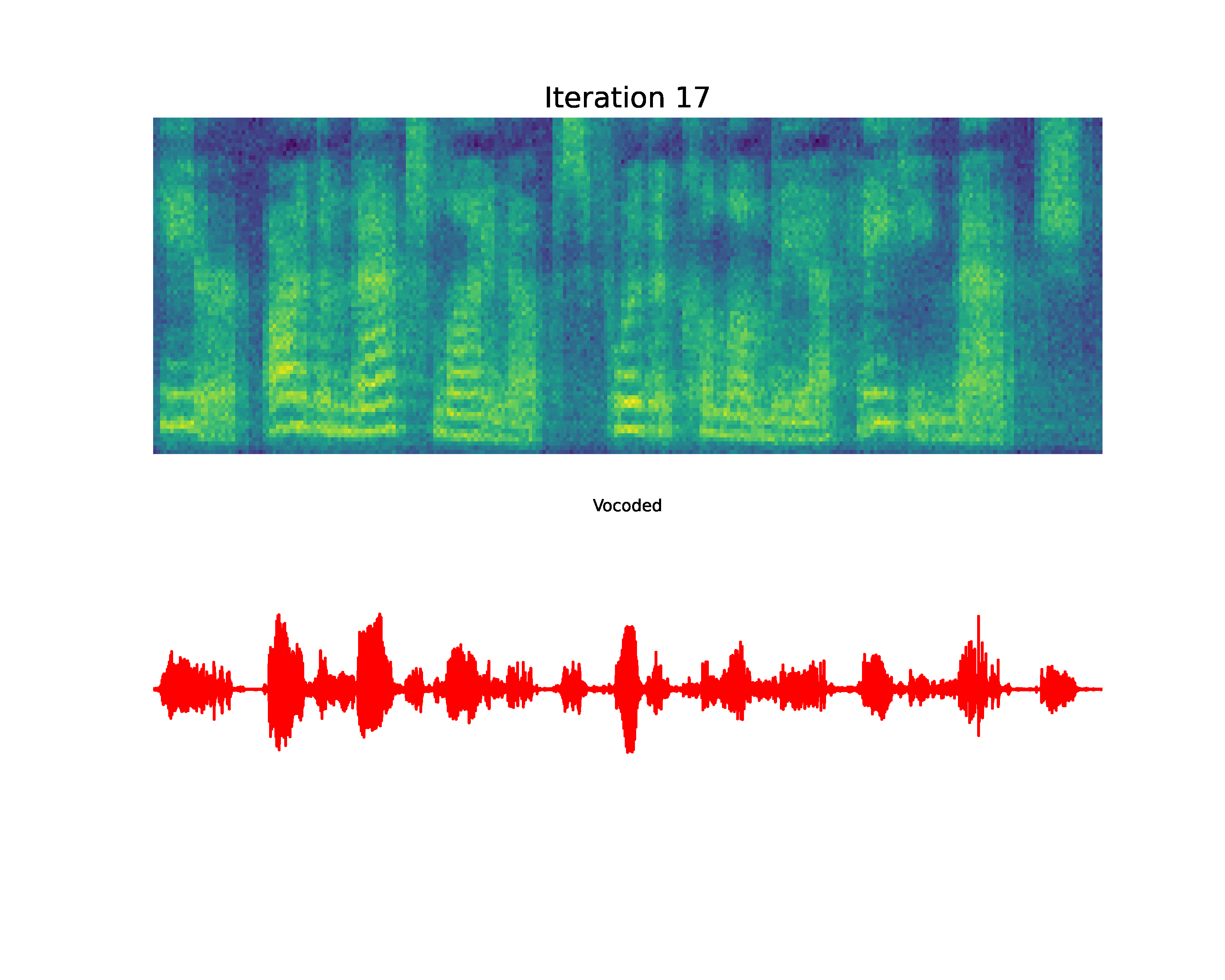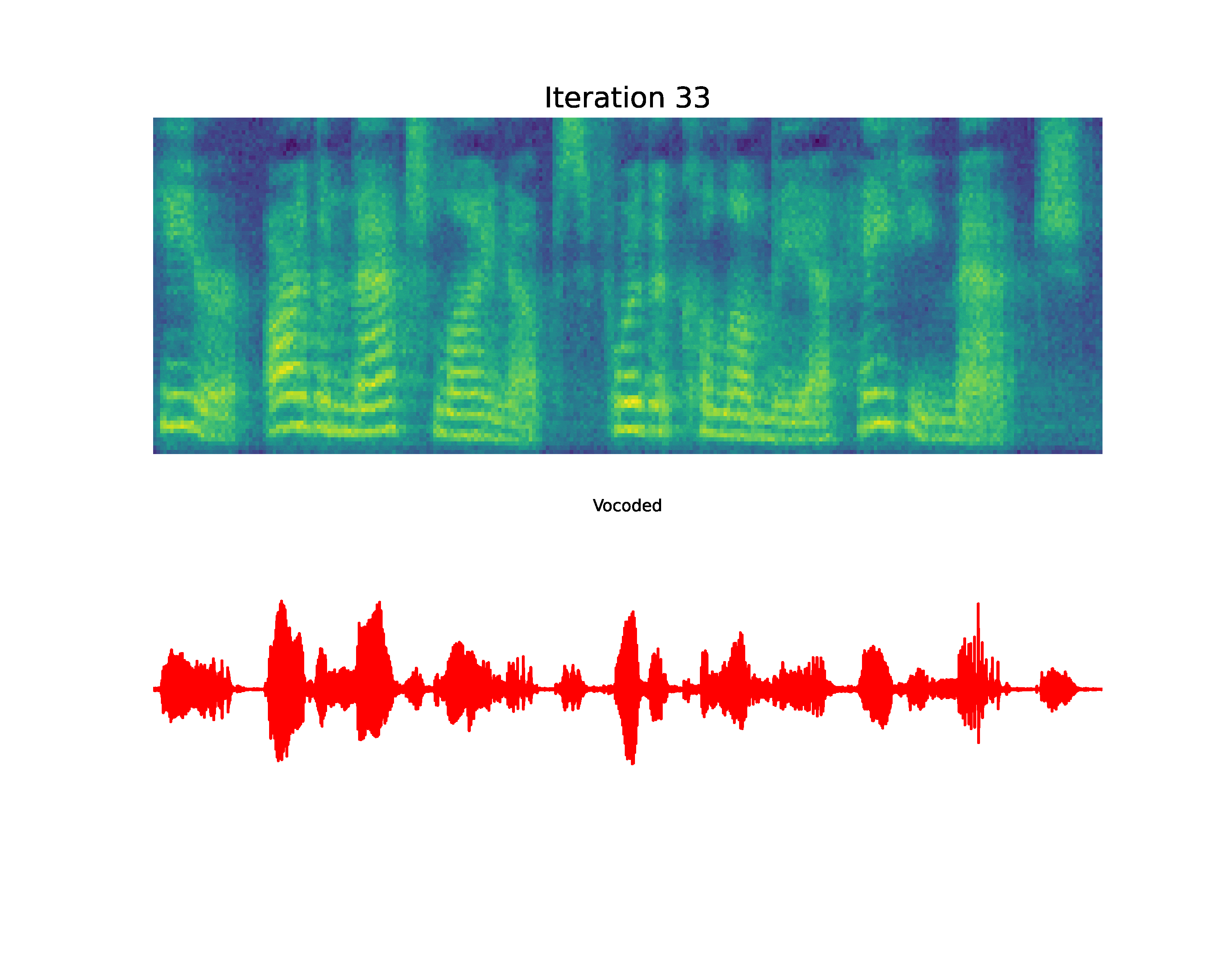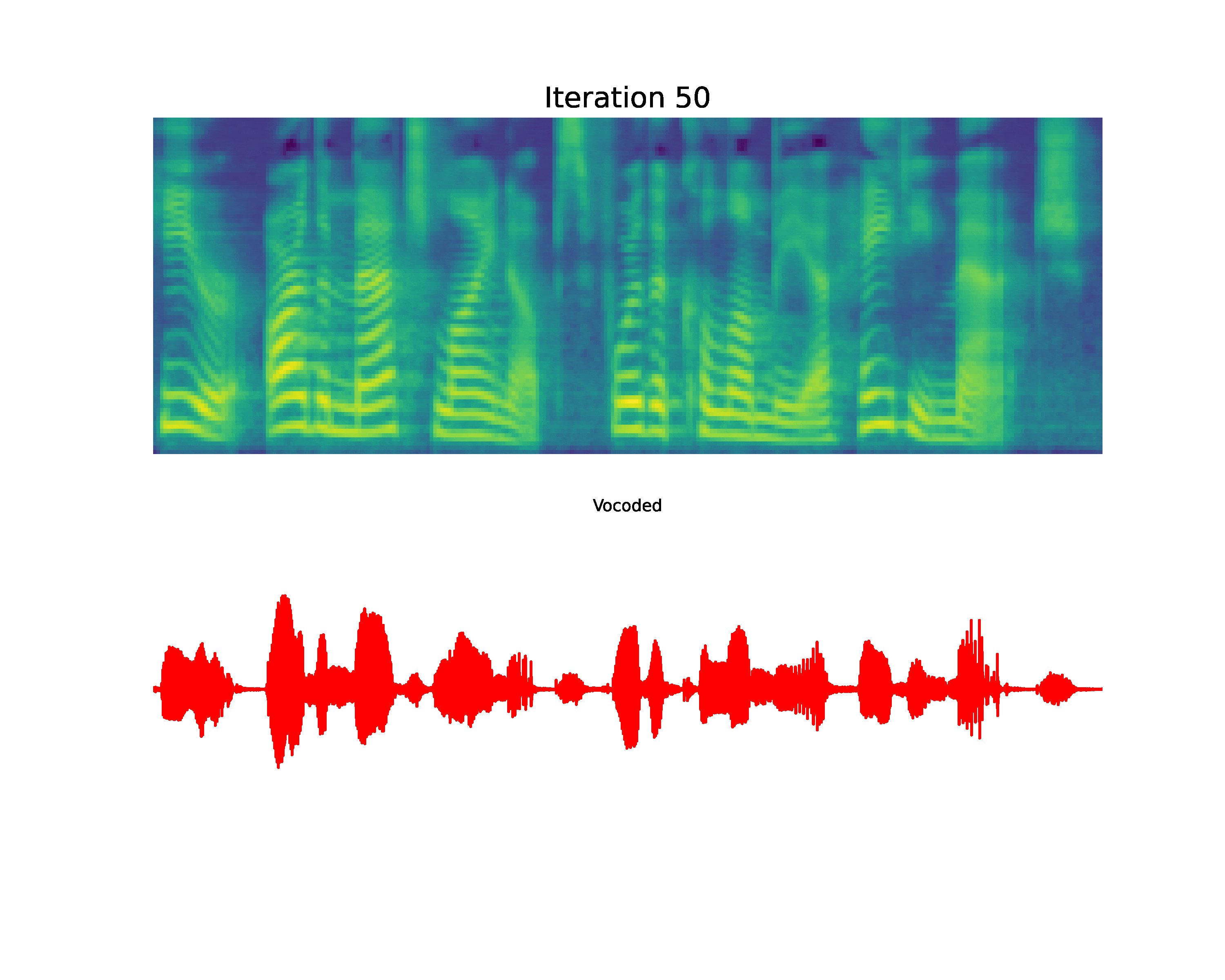
Comparison of generalized DPM vs. standard DPM:Our generalized DPM framework, where we use text encoder outputs µ as mean of decoder terminal distribution, results in the lower number of reverse diffusion steps (number of backward ODE solver iterations) necessary for high-quality mel-spectrogram generation. To show the difference we trained additional Grad-TTS model reconstructing mels from standard normal terminal distribution N(0, I). Note: Grad-TTS decoder neural network, which models gradients of data log-density, is still conditioned on text encoder outputs for both models.
Sampling mel-spectrograms with different temperature:Note: Grad-TTS-10 model is considered.
Controllable speech tempo:Text: Scientists at the CERN laboratory say they have discovered a new particle.
Examples from MOS evaluation:Note: Typically, only one model of Grad-TTS is trained. In the notation of Grad-TTS-N letter N corresponds to the overall number of timesteps used during inference to synthesize samples. The more is N the more accurate reverse diffusion trajectories are supposed to be restored resulting in better sound quality.
End-to-end pipeline synthesis:Note: we present results of our preliminary work, which is in progress.
|
⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀ |